
Flink
流处理
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
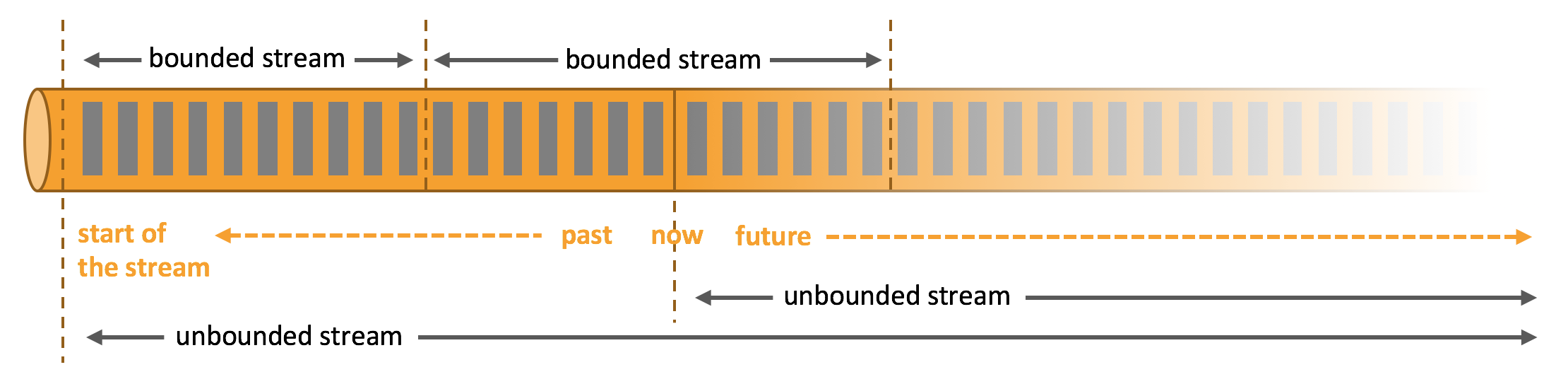
批处理是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
流处理正相反,其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
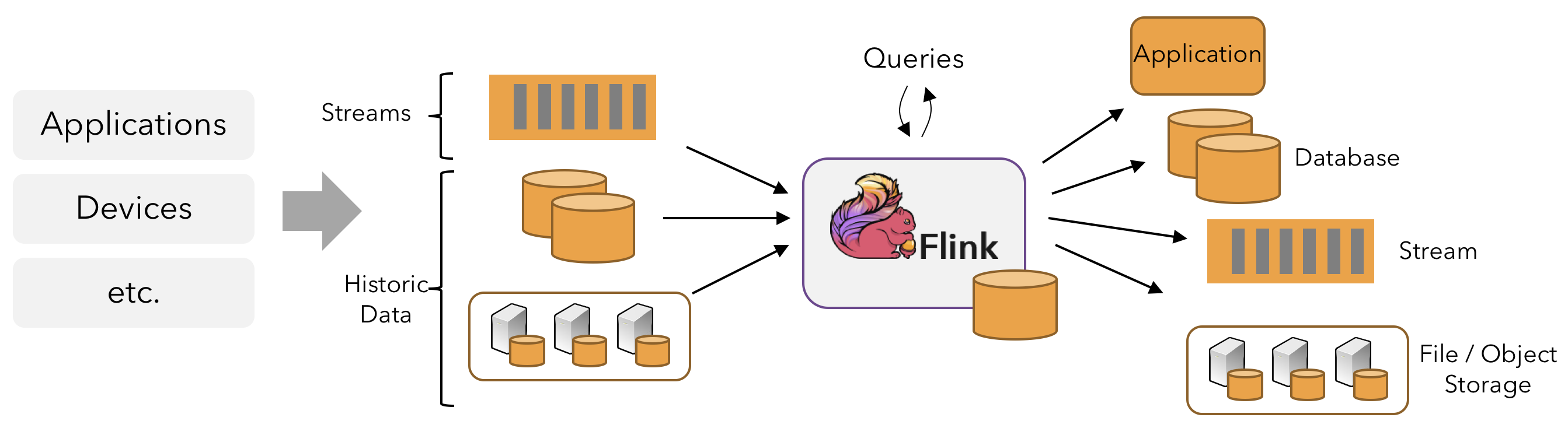
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。

通常,程序代码中的 transformation 和 dataflow 中的算子(operator)之间是一一对应的。但有时也会出现一个 transformation 包含多个算子的情况,如上图所示。
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种数据汇中。
DataStream API介绍和示例
Flink程序运行流程
1. 获取执行环境
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String… jarFiles)
2. 加载创建初始化数据
readTextFile()
addSource
..
3. 对数据在transformation operator
map
flatMap
filter
..
4. 指定计算结果的输出位置 sink
print()
writeAdText(String path)
addSink
..
5. 触发程序执行 execute
env.execute()
在sink是print时,不需要显示execute,否则会报错。因为在print方法里已经默认调用了execute。


