
Rust
Rust 教程
第一个 Rust 程序
Rust语言代码文件后缀名为.rs,如helloworld.rs。
|
使用rustc命令编译helloworld.rs文件:
|
编译后会生成helloworld可执行文件:
|
Rust 环境搭建
安装 Rust 编译工具
Rust 编译工具从链接 安装 Rust - Rust 程序设计语言 (rust-lang.org) 中下载的Rustup安装。下载好的Rustup在Windows 上是一个可执行程序 rustup-init.exe。(在其他平台上应该是rustup-init.sh)。
现在执行 rustup-init 文件:


上图显示的是一个命令行安装向导。
如果你已经安装MSVC(推荐),那么安装过程会非常的简单,输入 1 并回车,直接进入第二步。
如果你安装的是MinGW,那么你需要输入 2(自定义安装),然后系统会询问你 Default host triple?,请将上图中 default host triple的”msvc”改为”gnu”再输入安装程序:
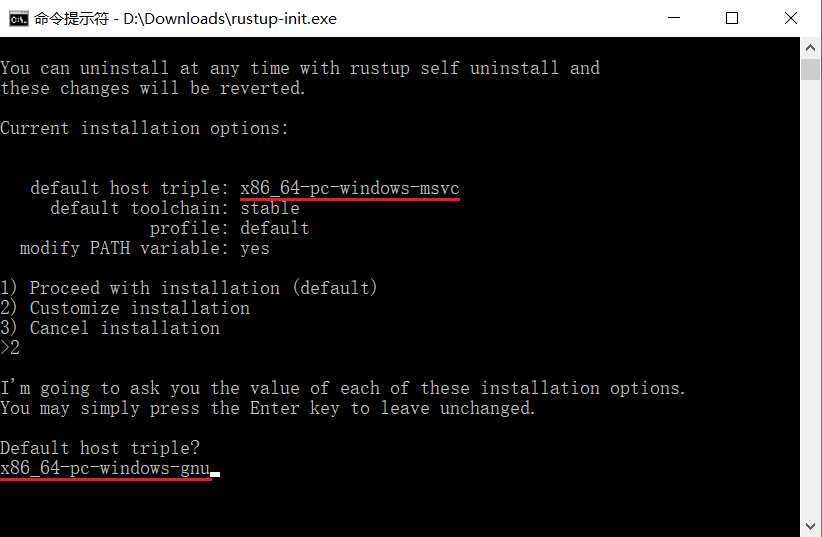
其他属性都默认。
设置完所有选项,会回到安装向导界面(第一张图),这时我们输入 1 并回车即可。
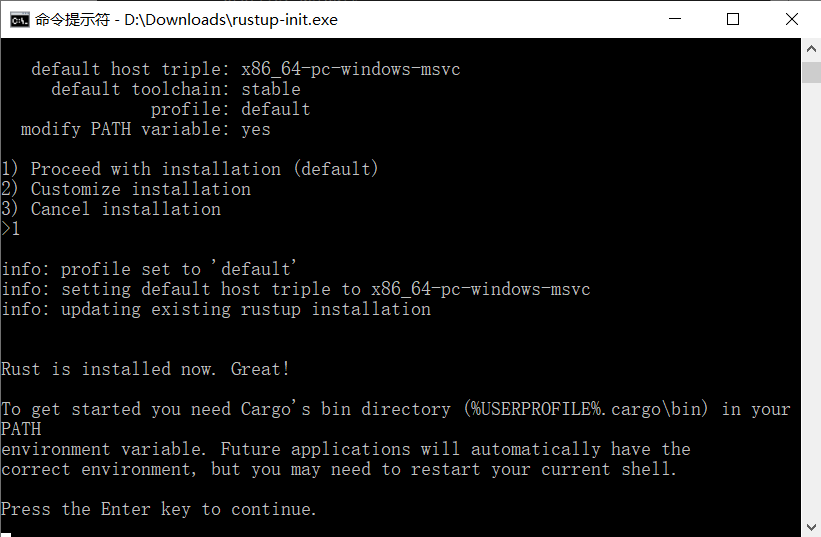
进行到这一步就完成了Rust的安装,可以通过以下命令测试:
|
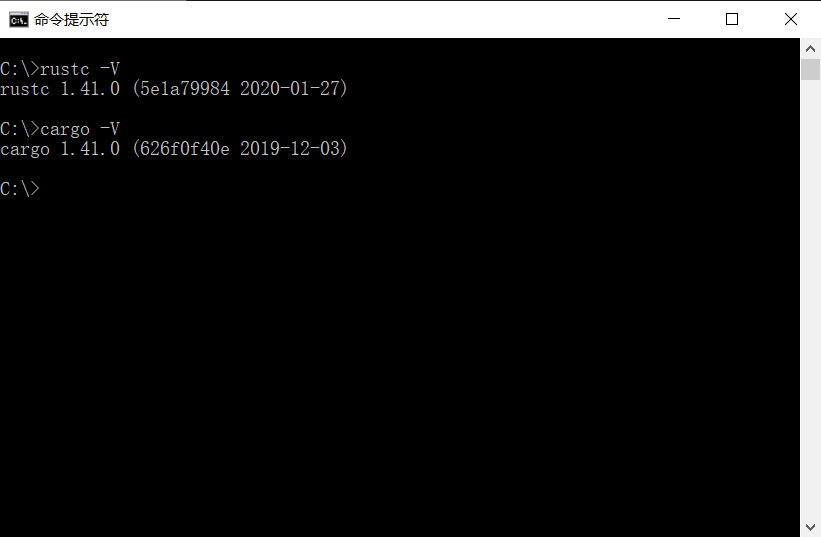
如果以上两个命令能够输出你安装的版本号,就是安装成功了。
搭建 Visual Studio Code 开发环境
安装rust-analyzer和Native Debug两个扩展。
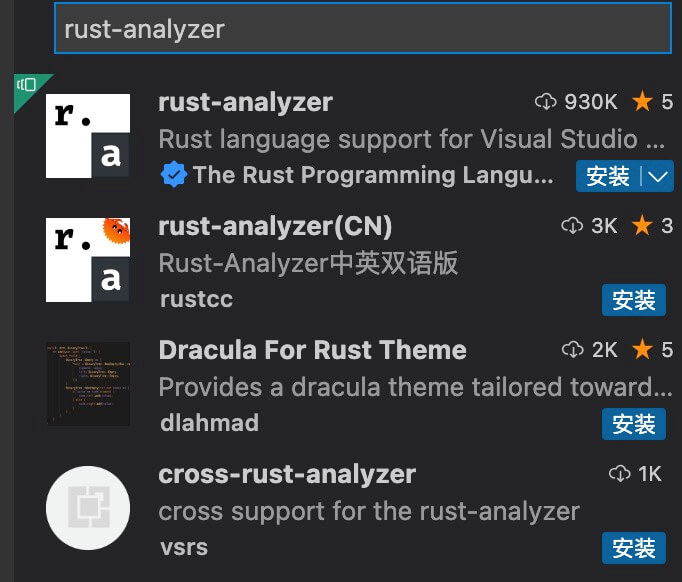
重新启动 VsCode,Rust 的开发环境就搭建好了。
现在新建一个文件夹,如 RustLearn。
在VsCode中打开新建的文件夹。
打开文件夹后,新建终端。
输入以下命令:
|
当前文件夹下会构建一个名叫 greeting 的 Rust 的工程目录。
在终端里输入以下三个命令:
|
系统在创建工程时会生成一个Hello World源程序main.rs,这时会被编译运行:
Rust 标准库中文版
该仓库包含 rust-src 组件的所有源代码文件,并对其所有的源代码进行翻译,主要包括对 Rust 核心库的翻译,Rust 标准库的翻译,以及其他一些资源。该仓库使用 Cmtor (我写的效率工具) 程序并借助 JSON 文件来完成翻译的所有工作,当 Rust 更新时,将尽可能为其生成中文翻译。
下载翻译好的 Rust 文档
每次在构建新的中文文档时,会修复之前构建结果中存在的问题,为了尽可能的保证翻译的准确性,本仓库只提供最新版本的构建。最新的构建结果会放在 dist 目录下,您可以手动跳转到该文件夹,下载最新的构建结果
使用 Rust 中文文档
- 在使用中文文档时,请注意版本号,中文文档版本和 Rust 版本号必须要保持一致。
- 必须使用
stable版本,不要使用beta和nightly版本。- 在翻译后的源代码中,一些文档的底部会存在一定量的内容为空的注释行,其实这是有意为之,请不要擅自修改和删除。如果您删除了它,就会导致
source-map失效,当source-map失效后,在调试源代码时就会出现执行位置和源代码位置不一致的严重问题。
请确保 Rust 已经安装好,并且可以正常工作。在 Rust 安装成功后,您还应该通过 rustup component add rust-src 命令来安装 rust-src 组件。当安装 rust-src 组件之后,请按照以下步骤进行操作:
- 在终端执行:
rustup default stable来切换到stable版本,并确保stable的版本与中文版文档所对应的版本一致 - 在终端执行
rustup show,然后在输出中找到rustup home所对应的路径,然后将其在资源管理器中打开 - 打开
toolchains的文件夹,在该文件夹下,找到您当前所使用的 Rust 工具链并将其打开,例如,在Windows平台上对应的是stable-x86_64-pc-windows-msvc文件夹 - 然后打开
lib/rustlib/src/rust目录,这个目录下的文件夹就是 Rust 标准库源代码所在的位置 - 将
lib/rustlib/src/rust/library文件夹下的所有内容保存一份副本,然后删除 - 下载本仓库对应的中文文档源文件,
dist目录下zip压缩包将其解压缩并将其下的library并放置到lib/rustlib/src/rust文件夹下 - 请确保您已经在 IDE 中安装 Rust 相关插件,例如,
vscode需要安装:rust-analyzer - 重新启动
IDE工具,中文文档的智能提示开始工作 - 愉快的编码!
Cargo 教程
Cargo 是什么
Cargo 是 Rust 的构建系统和包管理器。
Rust 开发者 常用 Cargo 来管理 Rust 工程和获取工程所依赖的库。在上个教程中我们曾使用 cargo new greeting 命令创建一个名为 greeting 的工程,Cargo 新建了一个名为 greeting 的文件夹并在里面部署了一个 Rust 工程最典型的文件结构。这个 greeting 文件夹就是工程本身。
Cargo 功能
Cargo 除了创建工程以外还具备构建(build)工程、运行(run)工程等一系列功能,构建和运行分别对应以下命令:
|
Cargo 还具有获取包、打包、高级构建等功能,详细使用方法参见 Cargo 命令。
|
在 VsCode 中配置 Rust 工程
Cargo 是一个不错的构建工具,如果使VsCode 与它相配合那么 VsCode 将会是一个十分便捷的开发环境。
在上一章中我们建立了 greeting 工程,现在我们用 VsCode 打开 greeting 文件夹(注意不是 RustLeanrning)。
打开 greeting 之后,在里面新建一个新的文件夹.vscode
Rust 输出到命令行
在正式学习 Rust 语言以前,我们需要先学会怎样输出一段文字到命令行,这几乎是学习每一门语言之前必备的技能,因为输出到命令行几乎是语言学习阶段程序表达结果的唯一方式。
在之前的 Hello, World 程序中大概已经告诉了大家输出字符串的方式,但并不全面,大家可能很疑惑为什么 println!( “Hello World”) 中的 println 后面还有一个 ! 符号,难道 Rust 函数之后都要加一个感叹号?显然并不是这样。println 不是一个函数,而是一个宏规则。这里不需要更深刻的挖掘宏规则是什么,后面的章节中会专门介绍,并不影响接下来的一段学习。
Rust 输出文字的方式主要有两种:println!() 和 print!()。这两个”函数”都是向命令行输出字符串的方法,区别仅在于前者会在输出的最后附加输出一个换行符。当用这两个”函数”输出信息的时候,第一个参数是格式字符串,后面是一串可变参数,对应着格式字符串中的”占位符”,这一点与 C 语言中的 printf 函数很相似。但是,Rust 中格式字符串中的占位符不是 “% + 字母” 的形式,而是一对 **{}**。
printlna.rs文件
|
使用rustc命令编译printlna.rs文件:
|
编译后会生成 printlna可执行文件:
|
以上程序的输出结果是:
|
如果我想把 a 输出两遍,那岂不是要写成:
|
其实有更好的写法:
|
在{}之间可以放一个数字,它将把之后的可变参数当做一个数组来访问,下标从0开始。
|
以上程序的输出结果是:
|
Rust 格式化代码
rustfmt
只会格式化单个Rust文件
|
cargo fmt
会格式化整个Rust项目
|
Rust 构建
基于cargo 创建的整个项目进行构建
|
默认按照Debug模式进行构建
若进行Release模式构建
|
Rust 运行
默认先按照Debug模式进行构建,然后再执行可执行文件
|
想只输出实际内容
|
Rust 基础语法
变量,基本类型,函数,注释和控制流,这些几乎是每种编程语言都具有的编程概念。
这些基础概念将存在于每个 Rust 程序中,及早学习它们将使你以最快的速度学习 Rust 的使用。
变量
首先必须说明,Rust 是强类型语言,但具有自动判断变量类型的能力。这很容易让人与弱类型语言产生混淆。
如果要声明变量,需要使用 let 关键字。例如:
|
只学习过 JavaScript 的开发者对这句话很敏感,只学习过 C 语言的开发者对这句话很不理解。
在这句声明语句之后,以下三行代码都是被禁止的:
|
第一行的错误在于当声明 a 是 123 以后,a 就被确定为整型数字,不能把字符串类型的值赋给它。
第二行的错误在于自动转换数字精度有损失,Rust 语言不允许精度有损失的自动数据类型转换。
第三行的错误在于 a 不是个可变变量。
前两种错误很容易理解,但第三个是什么意思?难道 a 不是个变量吗?
这就牵扯到了 Rust 语言为了高并发安全而做的设计:在语言层面尽量少的让变量的值可以改变。所以 a 的值不可变。但这不意味着 a 不是”变量”(英文中的 variable),官方文档称 a 这种变量为”不可变变量”。
如果我们编写的程序的一部分在假设值永远不会改变的情况下运行,而我们代码的另一部分在改变该值,那么代码的第一部分可能就不会按照设计的意图去运转。由于这种原因造成的错误很难在事后找到。这是 Rust 语言设计这种机制的原因。
当然,使变量变得”可变”(mutable)只需一个 mut关键字。
|
这个程序是正确的。
常量与不可变变量的区别
既然不可变变量是不可变的,那不就是常量吗?为什么叫变量?
变量和常量还是有区别的。在 Rust 中,以下程序是合法的:
|
但是如果 a 是常量就不合法:
|
变量的值可以”重新绑定”,但在”重新绑定”以前不能私自被改变,这样可以确保在每一次”绑定”之后的区域里编辑器可以充分的推理程序逻辑。虽然 Rust 有自动判断类型的功能,但有些情况下声明类型更加方便:
|
这里声明了 a 为无符号 64 位整型变量,如果没有声明类型,a 将自动被判断为有符号 32 位整型变量,这对于 a 的取值范围有很大的影响。
重影 (Shadowing)
重影的概念与其他面向对象语言里的”重写”(Override)或”重载”(Overload)是不一样的。重影就是刚才讲述的所谓”重新绑定”,之所以加引号就是为了在没有介绍这个概念的时候代替一下概念。
重影就是指变量的名称可以被重新使用的机制:
|
这段程序的运行结果:
|
重影与可变变量的赋值不是一个概念,重影是指用同一个名字重新代表另一个变量实体,其类型、可变属性和值都可以变化。但可变变量赋值仅能发生值的变化。
|
这段程序会出错:不能给字符串变量赋整型值。
Rust 数据类型
Rust 语言中的基础数据类型有以下几种。
整数型(Integer)
整数型简称整形,按照比特位长度和有无符号分为以下种类:
| 位长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
iszie 和 usize 两种整数类型是用来衡量数据大小的,它们的位长度取决于所运行的目标平台,如果是 32 位架构的处理器将使用 32 位位长度整型。
整数的表述方法有以下几种:
| 进制 | 例 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
| 字节(只能表示 u8 型) | b’A’ |
很显然,有的整数中间存在一个下划线,这种设计可以让人们在输入一个很大的数字时更容易判断数字的值大概是多少。
浮点整型(Floating-Point)
Rust 与其他语言一样支持 32 位浮点数(f32)和 64 位浮点数(f64)。默认情况下, 64.0 将表示 64 位浮点数,因为现代计算机处理器对两种浮点数计算的速度几乎相同,但 64 位浮点数精度更高。
|
数学运算
用一段程序反映数学运算:
|
许多运算符号之后加上 = 号是自运算的意思,例如:
sum + 1 等同于 sum = sum + 1。
注意:Rust 不支持 ++ 和 **–**,因为这两个运算符出现在变量的前后会影响代码可读性,减弱了开发者对变量改变的意识能力。
布尔型
布尔型用 bool 表示,值只能为 true 和 false。
字符型
字符型用 char 表示。
Rust 的 char 类型大小为 4 个字节,代表 Unicode 标量值,这意味着它可以支持中文,日文和韩文字符等非英文字符甚至表情符号和零宽度空格在 Rust 中都是有效的 char 值。
Unicode 值的范围从 U+0000 到 U+D7FF 和 U+E000 到 U+10FFFF(包括两端)。但是,”字符”这个概念并不存在与 Unicode 中,因此您对”字符”是什么的直觉可能与Rust中的字符概念不匹配。所以一般推荐使用字符串储存 UTF-8 文字(非英文字符尽可能地出现在字符串中)。
注意:由于中文文字编码有两种(GBK 和 UTF-8),所以编程中使用中文字符串有可能导致乱码的出现,这时因为源程序与命令行的文字编码不一致,所以在 Rust 中字符串和字符都必须使用 UTF-8 编码,否则编译器会报错。
复合类型
元组是一对( )包括的一组数据,可以包含不同种类的数据:
|
数组用一对[ ]包括的同类型数据。
|
Rust 函数
函数在 Rust 语言中是普遍存在的。
通过之前的章节已经可以了解到 Rust 函数的基本形式:
|
其中 Rust 函数名称的命名风格是小写字母以下划线分割:
|
运行结果:
|
注意,我们在源代码中的 main 函数之后定义了 another_function。Rust 不在乎您在何处定义函数,只需在某个地方定义它们即可。
函数参数
|
Rust 中定义函数如果需要具备参数必须声明参数名称和类型:
|
运行结果:
|
函数体的语句和表达式
Rust 函数体由一系列可以以表达式(Expression)结尾的语句(Statement)组成。到目前为止,我们仅见到了没有以表达式结尾的函数,但已经将表达式用作语句的一部分。
语句是执行某些操作且没有返回值的步骤。例如:
|
这个步骤没有返回值,所以以下语句不正确:
|
表达式有计算步骤且有返回值。以下是表达式(假设出现的标识符已经被定义):
|
Rust 中可以在一个用{}包括的块里编写一个较为复杂的表达式:
|
Rust 条件语句
Rust 中条件语句格式是这样的:
|
上述程序中,条件表达式 number < 5 不需要用小括号包括(注意,不需要不是不允许);但是 Rust 中的 if 不存在单语句不用加 {} 的规则,不允许使用一个语句代替一个块。尽管如此,Rust还是支持传统 else-if 语法的:
|
运行结果:
|
Rust 中的条件表达式必须是 bool 类型,例如下面的程序是错误的:
|
虽然 C/C++ 语言中的条件表达式用整数表示,非 0 即真,但这个规则在很多注重代码安全性的语言中是被禁止的。
结合之前章学习的函数体表达式我们加以联想:
|
在 Rust 中我们可以使用 if-else 结构实现类似于三元条件运算表达式 (A ? B : C) 的效果:
|
运行结果:
|
if 语句块的返回值也可以给 number 进行赋值
用 if 来赋值时,要保证每个分支返回的类型一样(这种说法也不完全准确),此处返回的 5 和 6 就是同一个类型,如果返回类型不一致就会报错
|
Rust 循环
Rust 的循环结果设计也十分成熟。
while 循环
while 循环是最典型的条件语句循环:
|
运行结果:
|
在 C 语言中 for 循环使用三元语句控制循环,但是 Rust 中没有这种用法,需要用 while 循环来代替:
C 语言
|
Rust
|
for 循环
for 循环是最常用的循环结构,常用来遍历一个线性数据结构(比如数组)。for 循环遍历数组:
|
运行结果:
|
这个程序中的 for 循环完成了对数组 a 的遍历。a.iter() 代表 a 的迭代器(iterator),在学习有关于对象的章节以前不做赘述。
当然,for 循环其实是可以通过下标来访问数组的:
|
运行结果:
|
loop 循环
某个循环无法在开头和结尾判断是否继续进行循环,必须在循环体中间某处控制循环的进行。如果遇到这种情况,我们经常会在一个 while (true) 循环体里实现中途退出循环的操作。
Rust 语言有原生的无限循环结构 —— loop:
|
运行结果:
|
loop 循环可以通过 break 关键字类似于 return 一样使整个循环退出并给予外部一个返回值。这是一个十分巧妙的设计,因为 loop 这样的循环常被用来当作查找工具使用,如果找到了某个东西当然要将这个结果交出去:
|
运行结果:
|
Rust 闭包
Rust 中的闭包是一种匿名函数,它们可以捕获并存储其环境中的变量。
闭包允许在其定义的作用域之外访问变量,并且可以在需要时将其移动或借用给闭包。
闭包在 Rust 中被广泛应用于函数编程、并发编程、和事件驱动编程等领域。
闭包在 Rust 中非常有用,因为它们提供了一种简洁的方式来编写和使用函数。
闭包在 Rust 中非常灵活,可以存储在变量中、作为参数传递,甚至作为返回值。
闭包通常用于需要短小的自定义逻辑的场景,例如迭代器、回调函数等。
闭包与函数的区别
| 特性 | 闭包 | 函数 |
|---|---|---|
| 匿名性 | 是匿名的,可存储为变量 | 有固定名称 |
| 环境捕获 | 可以捕获外部变量 | 不能捕获外部变量 |
| 定义方式 | ` | 参数 |
| 类型推导 | 参数和返回值类型可以推导 | 必须显式指定 |
| 存储与传递 | 可以作为变量、参数、返回值 | 同样支持 |
以下是 Rust 闭包的一些关键特性和用法:
闭包的声明
闭包的语法声明:
|
参数可以有类型注解,也可以省略,Rust 编译器会根据上下文推断它们。
|
闭包的参数和返回值: 闭包可以有零个或多个参数,并且可以返回一个值。
|
闭包的调用:闭包可以像函数一样被调用。
|
匿名函数
闭包在 Rust 中类似于匿名函数,可以在代码中以 {} 语法块的形式定义,使用 || 符号来表示参数列表,实例如下:
|
在这个示例中,add 是一个闭包,接受两个参数 a 和 b,返回它们的和。
捕获外部变量
闭包可以捕获周围环境中的变量,这意味着它可以访问定义闭包时所在作用域中的变量。例如:
|
以上代码中,闭包 square 捕获了外部变量 x,并在闭包体中使用了它。
闭包可以通过三种方式捕获外部变量:
- 按引用捕获(默认行为,类似
&T) - 按值捕获(类似
T) - 可变借用捕获(类似
&mut T)
|
说明:
- 闭包默认按引用捕获外部变量。
- 使用
move关键字可以强制按值捕获,将外部变量的所有权转移到闭包内。 - 如果闭包需要修改外部变量,需显式声明为
mut闭包。
移动与借用
闭包可以通过 move 关键字获取外部变量的所有权,或者通过借用的方式获取外部变量的引用。例如:
借用变量:默认情况下,闭包会借用它捕获的环境中的变量,这意味着闭包可以使用这些变量,但不能改变它们的所有权。这种情况下,闭包和外部作用域都可以使用这些变量。例如:
|
获取所有权:通过在闭包前添加 move 关键字,闭包会获取它捕获的环境变量的所有权。这意味着这些变量的所有权会从外部作用域转移到闭包内部,外部作用域将无法再使用这些变量。例如:
|
通过这两种方式,Rust 提供了灵活的机制来处理闭包与外部变量之间的关系,使得在编写并发、安全的代码时更加方便。
闭包的特性
闭包可以作为函数参数
闭包经常作为参数传递给函数,例如迭代器的 .map()、.filter() 方法:
|
这里的 Fn 是闭包的一个特性(trait),用于表示闭包可以被调用。
闭包可以作为返回值
闭包还可以作为函数的返回值。由于闭包是匿名的,我们需要使用 impl Trait 或 Box 来描述其类型。
使用 impl Fn 返回闭包
|
使用 Box<dyn Fn> 返回闭包
|
闭包特性(Traits)
闭包根据其捕获方式自动实现了以下三个特性:
Fn: 不需要修改捕获的变量,闭包可以多次调用。FnMut: 需要修改捕获的变量,闭包可以多次调用。FnOnce: 只需要捕获所有权,闭包只能调用一次。
|
Rust 所有权
计算机程序必须在运行时管理它们所使用的内存资源。
大多数的编程语言都有管理内存的功能:
C/C++ 这样的语言主要通过手动方式管理内存,开发者需要手动的申请和释放内存资源。但为了提高开发效率,只要不影响程序功能的实现,许多开发者没有及时释放内存的习惯。所以手动管理内存的方式常常造成资源浪费。
Java 语言编写的程序在虚拟机(JVM)中运行,JVM 具备自动回收内存资源的功能。但这种方式常常会降低运行时效率,所以 JVM 会尽可能少的回收资源,这样也会使程序占用较大的内存资源。
所有权对大多数开发者而言是一个新颖的概念,它是 Rust 语言为高效使用内存而设计的语法机制。所有权概念是为了让 Rust 在编译阶段更有效地分析内存资源的有用性以实现内存管理而诞生的概念。
所有权规则
所有权有以下三条规则:
- Rust中的每一个值都有一个变量,称为其所有者。
- 一次只能有一个所有者。
- 当所有者不在程序运行范围时,该值将被删除。
这三条规则是所有权概念的基础。
接下来介绍与所有权概念有关的概念。
变量范围
我们用下面这段程序描述变量范围的概念:
|
变量范围是变量的一个属性,其代表变量的可行域,默认从声明变量开始有效直到变量所在域结束。
内存和分配
如果我们定义了一个变量并给它赋予一个值,这个变量的值存在于内存中。这种情况很普遍。但如果我们需要储存的数据长度不确定(比如用户输入的一串字符串),我们就无法在定义时明确数据长度,也就无法在编译阶段令程序分配固定长度的内存空间供数据储存使用。(有人说分配尽可能大的空间可以解决问题,但这个方法很不文明)。这就需要提供一种在程序运行时程序自己申请使用内存的机制—-堆。本章所讲的”内存资源”都指的是堆所占用的内存空间。
有分配就有释放,程序不能一直占用某个内存资源。因此决定资源是否浪费的关键因素就是资源有没有及时的释放。
我们把字符串样例程序用 C 语言等价编写:
|
很显然,Rust 中没有调用 free 函数来释放字符串 s 的资源(我知道这样在 C 语言中是不正确的写法,因为 “schar” 不在堆中,这里假设它在)。Rust 之所以没有明确释放的步骤是因为在变量范围结束的时候, Rust 编译器自动添加了调用释放资源函数的步骤。这个机制看似很简单了:它不过是帮助程序员在适当的地方添加了一个释放资源的函数调用而已。但这种简单的机制可以有效地解决一个史上最令程序员头疼的编程问题。
变量与数据交互的方式
变量与数据交互方式主要有移动(Move)和克隆(Clone)两种:
移动
多个变量可以在 Rust 中以不同的方式与相同的数据交互:
|
这个程序将值 5 绑定到变量 x,然后将 x 的值复制并赋值给变量 y。现在栈中将有两个值 5。此情况中的数据是”基本数据”类型的数据,不需要存储在堆中,仅在栈中的数据的”移动”方式是直接复制,这不会花费更长的时间或更多的存储空间。”基本数据”类型有这些:
- 所有整数类型,例如 i32、u32、i64 等。
- 布尔类型 bool,值为 true 或 false 。
- 所有浮点类型,f32 和 f64。
- 字符类型 char。
- 仅包含以上类型数据的元组(Tuples)。
但如果发生交互的数据在堆中就是另外一种情况:
|
第一步产生一个 String 对象,值为 “hello”。其中 “hello” 可以认为是类似于长度不确定的数据,需要在堆中存储。
第二步的情况略有不同(这不是完全真的,仅用来对比参考):
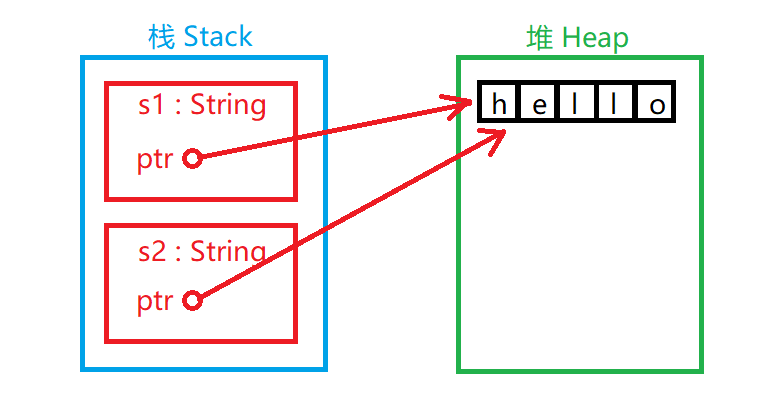
如图所示:两个 String 对象在栈中,每个 String 对象都有一个指针指向堆中的 “hello” 字符串。在给 s2 赋值时,只有栈中的数据被复制了,堆中的字符串依然还是原来的字符串。
前面我们说过,当变量超出范围时,Rust 自动调用释放资源函数并清理该变量的堆内存。但是 s1 和 s2 都被释放的话堆区中的 “hello” 被释放两次,这是不被系统允许的。为了确保安全,在给 s2 赋值时 s1 已经无效了。没错,在把 s1 的值赋给 s2 以后 s1 将不可以再被使用。下面这段程序是错的:
|
所以实际情况是:
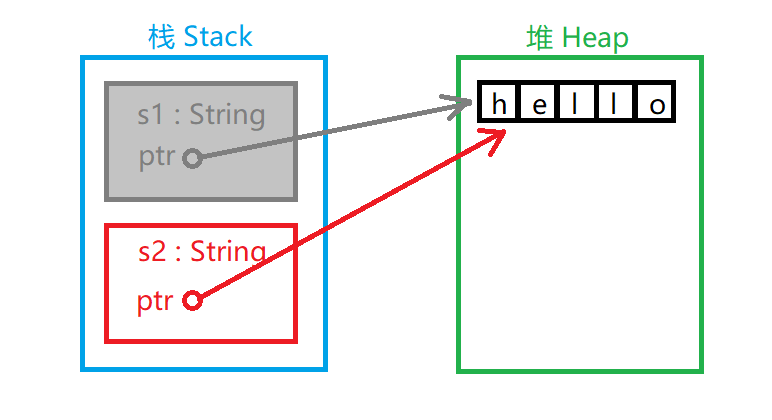
s1 名存实亡。
克隆
Rust会尽可能地降低程序的运行成本,所以默认情况下,长度较大的数据存放在堆中,且采用移动的方式进行数据交互。但如果需要将数据单纯的复制一份以供他用,可以使用数据的第二种交互方式——克隆。
|
运行结果:
|
这里是真的将堆中的 “hello” 复制了一份,所以 s1 和 s2 都分别绑定了一个值,释放的时候也会被当作两个资源。
当然,克隆仅在需要复制的情况下使用,毕竟复制数据会花费更多的时间。
涉及函数的所有权限制
对于变量来说这是最复杂的情况了。
如果将一个变量当作函数的参数传给其他函数,怎样安全的处理所有权呢?
下面这段程序描述了这种情况下所有权机制的运行原理:
|
如果将变量当作参数传入函数,那么它和移动的效果是一样的。
函数返回值的所有权机制
|
引用与租借
引用(Reference)是 C++ 开发者较为熟悉的概念。
如果你熟悉指针的概念,你可以把它看作一种指针。
实质上”引用”是变量的间接访问方式。
|
运行结果:
|
& 运算符可以取变量的”引用”。
当一个变量的值被引用时,变量本身不会被认定无效。因为”引用”并没有在栈中复制变量的值:
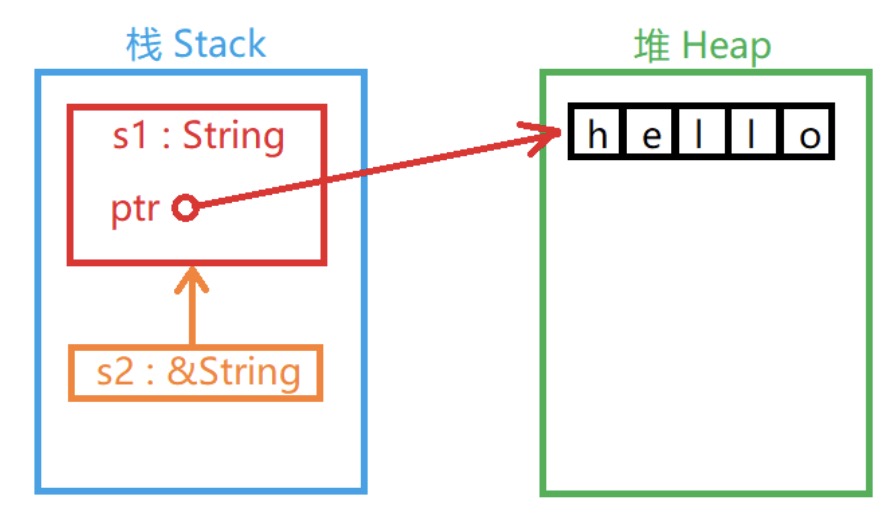
函数参数传递的道理一样:
|
运行结果:
|
引用不会获得值的所有权。
引用只能租借(Borrow)值的所有权。
引用本身也是一个类型并具有一个值,这个值记录的是别的值所在的位置,但引用不具有所指值的所有权:
|
这段程序不正确:因为 s2 租借的 s1 已经将所有权移动到 s3,所以 s2 将无法继续租借使用 s1 的所有权。如果需要使用 s2 使用该值,必须重新租借:
|
这段程序是正确的。
既然引用不具有所有权,即使它租借了所有权,它也只享有使用权(这跟租房子是一个道理)。
如果尝试利用租借来的权利来修改数据会被阻止:
|



